Loạt bài viết này sẽ giúp chúng ta hiểu sâu về Q-Learning cùng với cách xây dựng và triển khai hai thuật toán quan trọng là Adaptive Dynamic Programming và Monte Carlo.
Q-Learning là một thuật toán Reinforcement Learning (Học Tăng cường). Tuy không dùng đến Neural Network (Mạng Nơ-ron) nhưng thuật toán này vẫn có thể giải quyết được rất nhiều bài toán trong thực tế.
Loạt bài viết này sẽ giúp chúng ta hiểu sâu về Q-Learning cùng với cách xây dựng và triển khai hai thuật toán quan trọng là Adaptive Dynamic Programming (Quy hoạch Động Thích ứng) và Monte Carlo (Mô phỏng Monte Carlo).
Khuyến nghị đọc trước Phần 1 để sẵn sàng trước khi đi vào bài viết này.
Nhắc lại
Chúng ta đã biết cách hoạt động và các khái niệm quan trọng của Markov Decision Process trong series trước. Tuy nhiên đây chỉ là một công cụ dùng để khái quát hoá bài toán Reinforcement Learning (Học Tăng cường). Thực tế, Agent thường không có khả năng biết được các thông tin quan trọng như Reward hay Transition Model.
Để hiểu đơn giản, MDP là một bài toán giúp Agent lập kế hoạch, vì lúc này Agent đã biết được các thông tin quan trọng. Trong khi đó Q-Learning bao gồm cả quá trình học để có được các thông tin này.
Q-Learning (Học Q) là một thuật toán giúp Agent có thể học được các thông tin này thông qua việc thử nhiều lần và rút ra kinh nghiệm. Để có thể triển khai được thuật toán này, chúng ta sẽ cần tìm hiểu qua hai thuật toán quan trọng là Adaptive Dynamic Programming (Quy hoạch Động Thích ứng) và Monte Carlo (Mô phỏng Monte Carlo).
Khái niệm
Giống với ADP, Monte Carlo cũng là một thuật toán giúp Agent có thể học được các thông tin quan trọng thông qua việc thử nhiều lần và rút ra kinh nghiệm. Tuy nhiên thuật toán này sẽ không cần dùng đến Reward và Transition Model như ADP.
Do đó, ta gọi Monte Carlo là một thuật toán Model-free (Không dựa trên Model), trong khi ADP là thuật toán Model-based (Dựa trên Model).
Nguồn gốc cái tên Monte Carlo
Monte Carlo thực chất là một phương pháp được sử dụng rất nhiều trong thống kê để ước tính giá trị của một hàm số thông qua việc lấy các sample (mẫu) ngẫu nhiên lặp đi lặp lại nhiều lần.
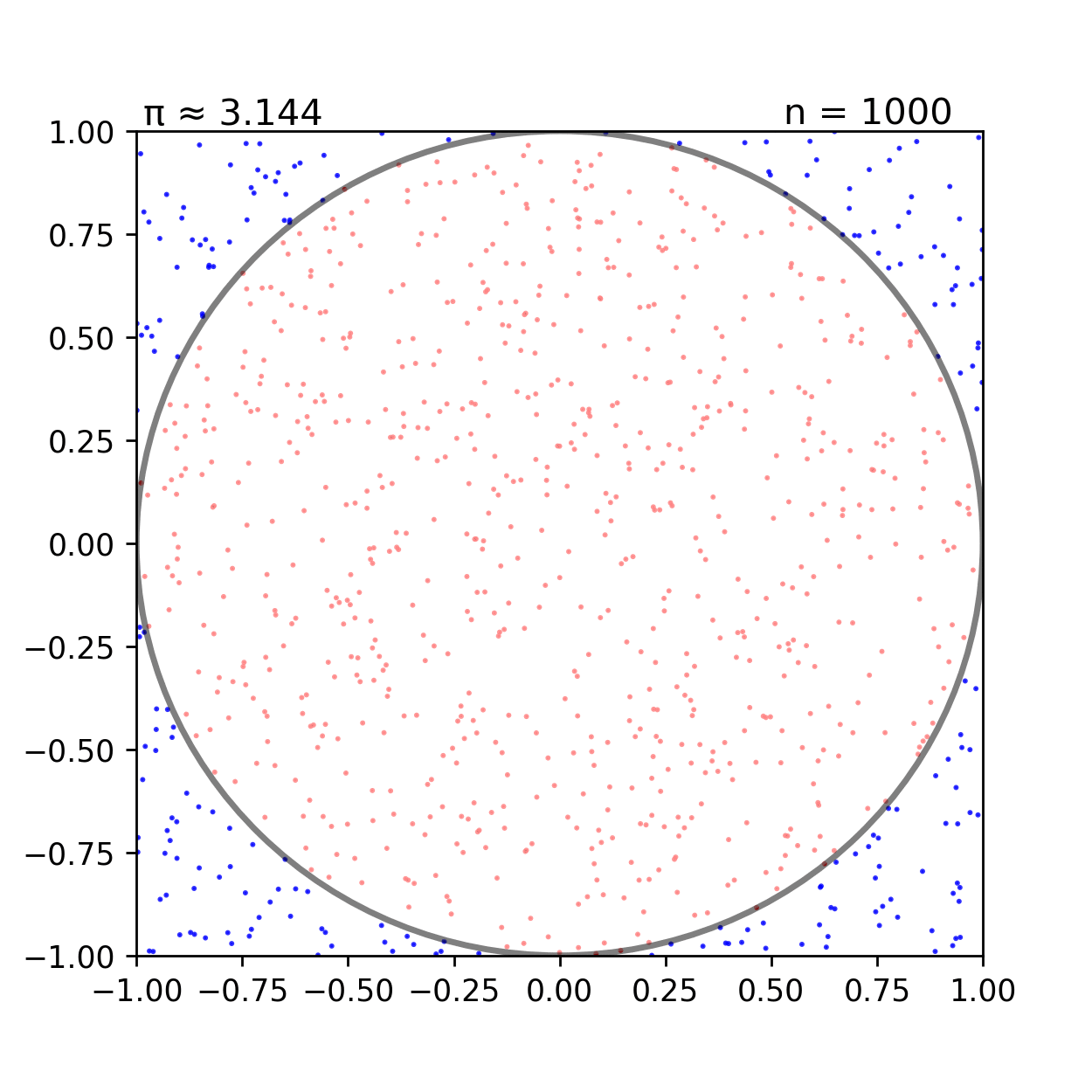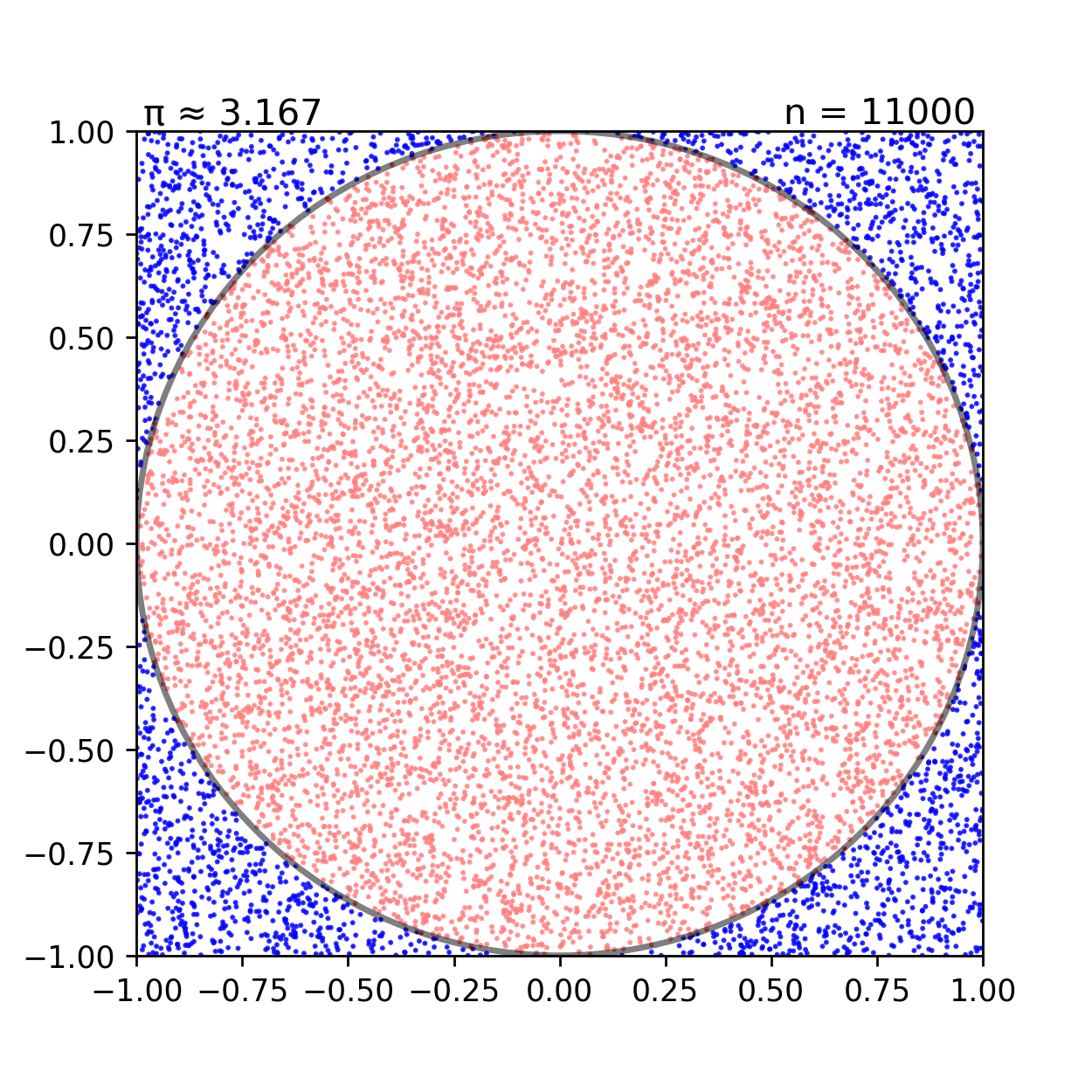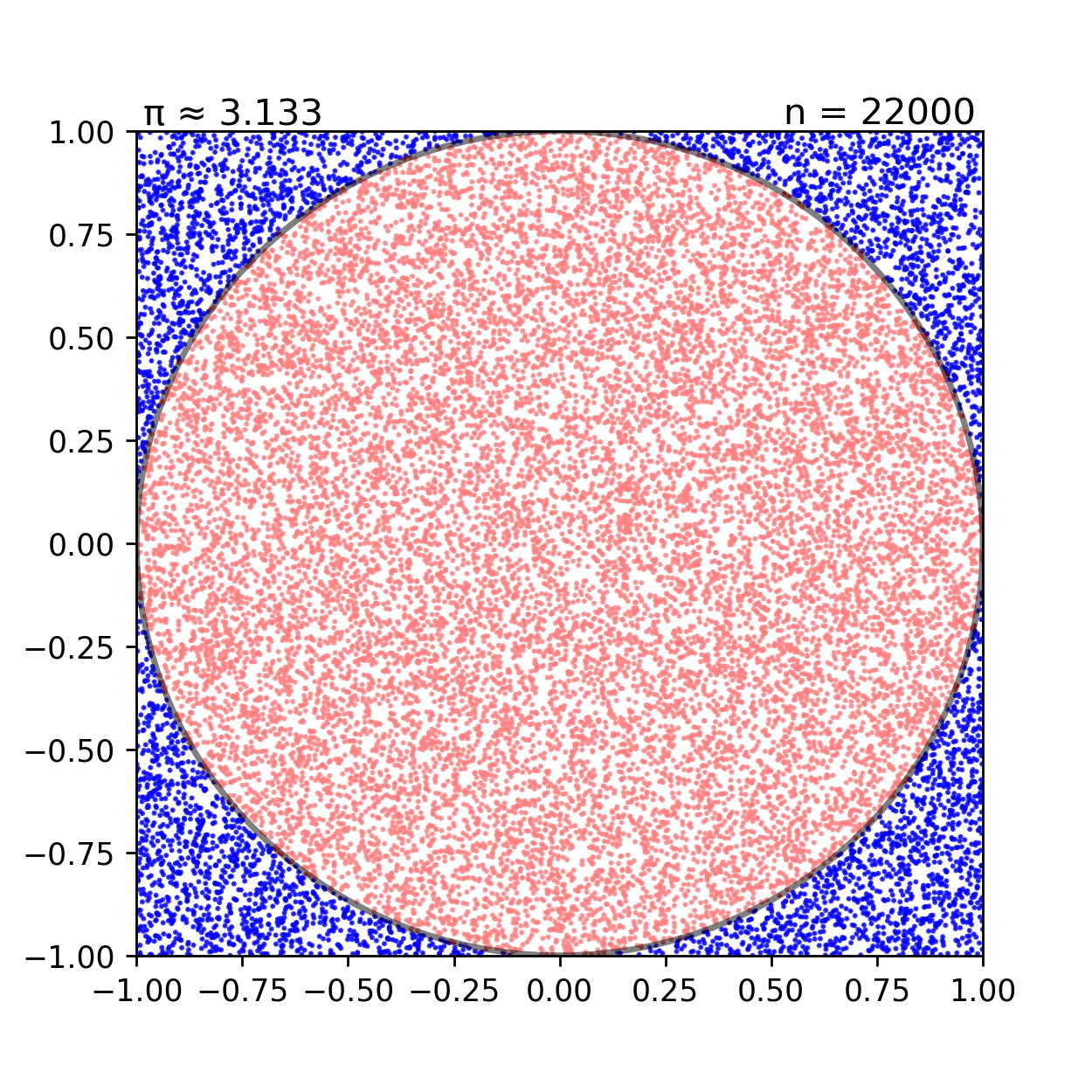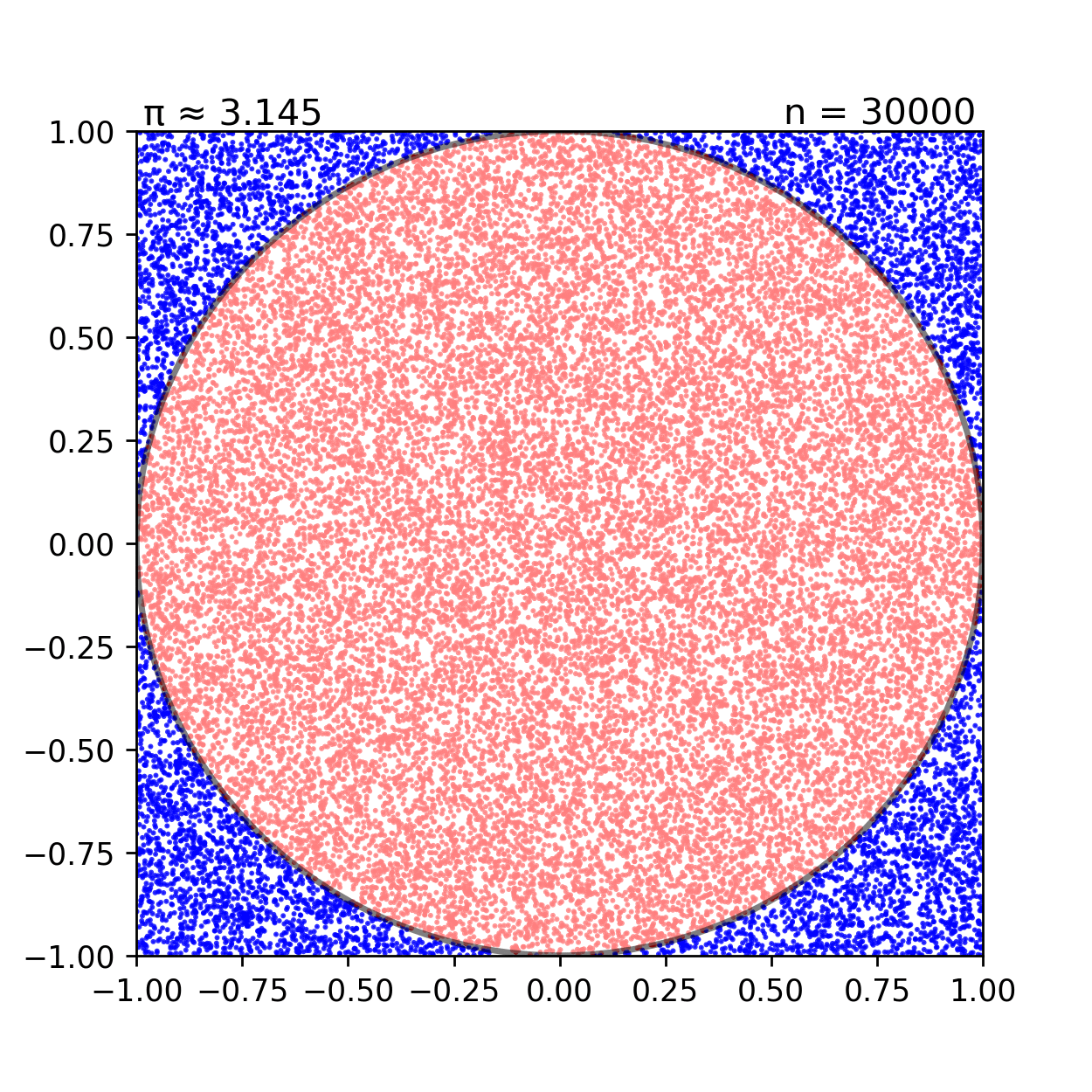
Một ví dụ điển hình để hình dung về thuật toán Monte Carlo là việc ước tính giá trị π (pi) thông qua việc tạo ra các điểm ngẫu nhiên trong một hình vuông và đếm số điểm nằm trong một hình tròn nằm trong hình vuông đó:
Ví dụ về Monte Carlo
Cho đường tròn x2+y2=1 nội tiếp hình vuông x∈[−1,1],y∈[−1,1]. Giả sử chúng ta tạo ra N điểm (xi,yi) ngẫu nhiên trong hình vuông này. Khi đó, ta sẽ theo dõi số điểm nằm trong hình tròn Ncircle theo thuật toán sau:
Khi đó ta có thể xấp xỉ giá trị π thông qua việc đếm số điểm nằm trong hình tròn và hình vuông.
Xây dựng Monte Carlo
Như ta đã biết, MDP và ADP là các thuật toán xác định Policy bằng cách ước tính Value của mỗi State. Để làm được điều này, chúng ta sẽ cần tới Reward và Transition Model. Vì vậy để bỏ đi hai yếu tố này, chúng ta sẽ cần phải thiết lập một thành phần mới với mục đích tương tự. Và thành phần (rất) quan trọng này chính là Q-Value (Giá trị Q), thứ sẽ ảnh hưởng đến các bài toán Reinforcement Learning (Học Tăng cường) sau này.
Hãy để ý rằng, Reward R nhận State s làm đầu vào và Transition Model T nhận cặp State-Action (s,a) làm đầu vào. Và cuối cùng sử dụng chúng để xác định V(s).
Tuy nhiên chúng ta có thể gộp cả 2 thành phần này lại với nhau thành một thành phần gọi là Q(s,a). Thành phần này sẽ nhận cặp State-Action (s,a) làm đầu vào và trả về một giá trị thể hiện mức độ "tốt" của cặp này hệt như chức năng của Value nhưng đơn giản hơn.
Hãy sử dụng lại công thức tính Value (theo Value Iteration):
Giờ đây, chỉ cần ước tính được Q(s,a) thì chúng ta có thể chọn ra được Action tốt nhất cho State s mà không cần phải xử lí qua Reward và Transition Model.
Tương tự như trên, với công thức tính Policy (theo Policy Iteration):
π(s)=argamax[∑T(s′∣s,a)V(s′)]
Ta có thể cung cấp thêm Reward và Discount Factor vào công thức trên:
Tại State s0, ta thực hiện Action a0 và nhận được Reward r0 và State s1. Tiếp tục thực hiện Action a1, ta sẽ nhận được Reward r1 và State s2. Và cứ tiếp tục như vậy cho đến khi đạt đến State sp.
Ta sẽ định nghĩa lại C(s,a) là Cucumlative Reward của một Episode e bắt đầu từ State s và Action a (bỏ qua Random Rate):
Chúng ta không cần quan tâm Episode này bắt đầu từ State nào, miễn là trong đó có cặp State-Action cần tính (ví dụ s3,a1). Ta sẽ ngầm giả sử Episode bắt đầu tại đây và tính Cucumlative Reward bắt đầu từ cặp State-Action này trở đi.
C(s3,a1)=r0+r1+r3+⋯+r2+r2+r0+…
Vì là First-visit nên trong một Episode, Cucumlative Reward chỉ được tính một lần duy nhất cho mỗi cặp State-Action.
Every-visit
Tuy nhiên Every-visit không giống vậy, ta sẽ tính Cucumlative Reward cho mỗi lần xuất hiện của cặp State-Action trong một Episode. Với ví dụ trên, ta sẽ có:
Tuy nhiên đây chỉ là Episode e0, chúng ta cần nhiều hơn thế nữa để lấp đầy tất cả cặp State-Action. Vì vậy, chúng ta sẽ thực hiện việc này N Episode và sau đó lấy trung bình của các C-Table này. Đây chính là Q-Table (Bảng Q).
Q=N1i=1∑NCi
Công thức trên khá khó để có thể cập nhật lại Q-Table sau mỗi Episode vì chúng ta phải tính tổng toàn bộ C-Table từ đầu, hơn nữa, chúng ta sẽ không lưu lại các C-Table trước đó.
Vì vậy, chúng ta sẽ biến đổi một chút để có thể cập nhật Q-Table bằng Q-Table hiện tại và C-Table tính được:
Chúng ta đã qua hết những thứ cần thiết để xây dựng thuật toán. Các bước thực hiện của thuật toán Monte Carlo giống với ADP, đều gồm 3 bước dưới đây:
Actute
Đây là bước Agent lựa chọn Action a để thực hiện dựa trên State hiện tại s và Policy π.
Bước này không có thay đổi gì với ADP. Cũng dựa vào một hệ số phân rã ϵ để quyết định xem Agent sẽ thực hiện Exploration hay Exploitation. Nếu là Exploration thì Agent sẽ lựa chọn Action a ngẫu nhiên, ngược lại sẽ lựa chọn Action a tốt nhất, chính là từ Policy π.
α←U(0,1){a←RAa=π(s)if α<ϵotherwise
Percept
Đây là bước cung cấp cho Agent những thông tin cần thiết. Bao gồm State hiện tại s, Action a đã chọn ở bước Actuate, State mới s′ và Reward r đã nhận được.
Q-Table sẽ được cập nhật dựa trên thông tin này bằng những công thức đã xây dựng ở trên.
Thuật toán này có nghĩa là một khi cặp State-Action (s,a) đã xuất hiện trong Episode hiện tại, Cumulative Reward của nó sẽ phải được cập nhật với mỗi Reward r mới được thêm vào.
Policy Improvement
Với ADP, chúng ta có Reward và Transition Model nên có thể dùng một trong các thuật toán MDP để thực hiện Policy Improvement. Tuy nhiên với Monte Carlo, chúng ta sẽ phải xây dựng một thuật toán mới để thực hiện việc này.
Sau mỗi Episode, chúng ta sẽ khởi tạo lại C[s,a] và visited, chỉ giữ lại Q[s,a] và N[s,a] để phục vụ Monte Carlo.
Kết luận
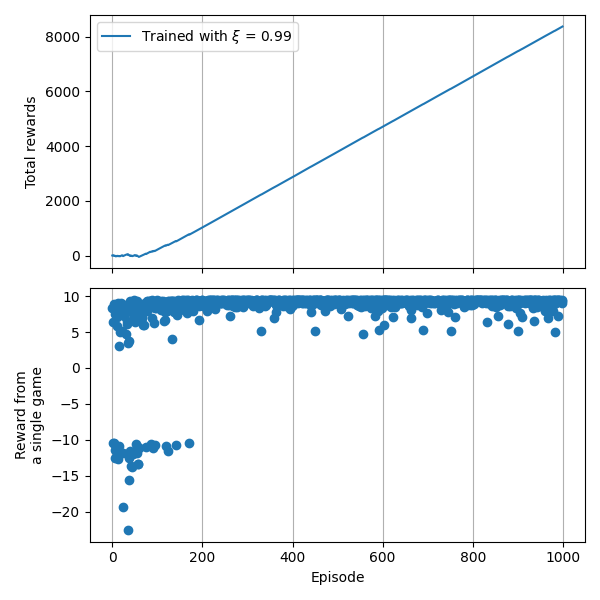
Lấy ví dụ từ series trước, sau khi chạy thuật toán với 100 Episode, chúng ta có tổng Reward nhận được như sau:
Reward nhận được sau 1000 Episode
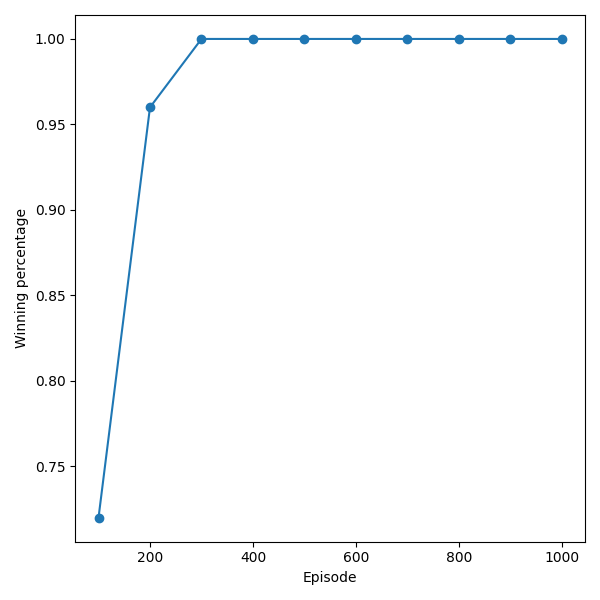
Còn đây là tỉ lệ thắng qua mỗi Episode:
Tỉ lệ thắng nhận được sau 1000 Episode
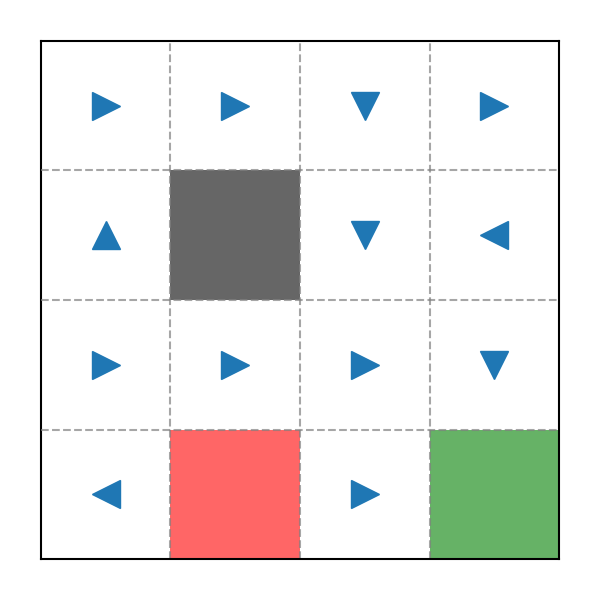
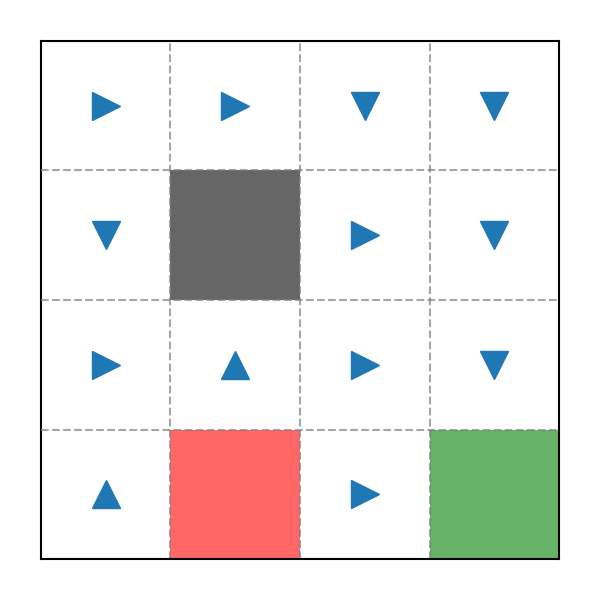
Cuối cùng là Policy tính được:
Policy sau 1000 Episode
Đây là input từ ADP và MDP, có thể thấy nó không hiệu quả lắm và Policy cũng không hợp lí. Bởi vì không như ADP hay MDP, Monte Carlo rất phụ thuộc vào Reward và nó ảnh hưởng trực tiếp đến Policy. Do đó, chúng ta hãy thử với bộ Reward mới: