Hiểu sâu về Markov Decision Process (Phần 3 - Value Iteration)
Loạt bài viết này sẽ giúp chúng ta hiểu sâu về Markov Decision Process cùng với cách xây dựng và triển khai hai thuật toán phổ biến là Policy Iteration và Value Iteration
Markov Decision Process (MDP) là một bài toán Dynamic Programming (Quy hoạch Động) được sử dụng rất nhiều trong các lĩnh vực công nghệ và đóng vai trò đặc biệt trong Reinforcement Learning (Học Tăng cường). MDP được sử dụng để mô hình hóa việc ra quyết định trong các tình huống mà kết quả là một phần ngẫu nhiên và một phần dưới sự điều khiển của người ra quyết định.
Loạt bài viết này sẽ giúp chúng ta hiểu sâu về Markov Decision Process cùng với cách xây dựng và triển khai hai thuật toán phổ biến là Policy Iteration và Value Iteration.
Khuyến nghị đọc trước Phần 2 để sẵn sàng trước khi đi vào bài viết này.
Nhắc lại
Ở phần trước chúng ta đã biết được khái niệm Value và thuật toán Policy Iteration. Thuật toán này sẽ tìm ra Policy tối ưu bằng cách tạo Policy ngẫu nhiên trước, sau đó thực hiện các lần lặp để cải tiến Policy cho đến khi không còn thay đổi nào nữa.
Tuy nhiên việc thuật toán này tương đối phức tạp khi mỗi lần lặp phải thực hiện 2 bước là Policy Evaluation và Policy Improvement.
Chúng ta sẽ sử dụng lại các quy ước và những gì đã triển khai ở phần trước.
Khái niệm
Value Iteration (Lặp theo Value) là một thuật toán để tìm ra Policy tối ưu. Trái ngược với Policy Iteration (Lặp theo Policy), thuật toán này sẽ tìm ra Policy tối ưu bằng cách tạo Value ngẫu nhiên trước, sau đó thực hiện các lần lặp để cải tiến Value cho đến khi không còn thay đổi nào nữa.
Mỗi lần lặp sẽ chỉ thực hiện 1 bước là Value Evaluation (Đánh giá Value), bước này là sự kết hợp của 2 bước Policy Evaluation và Policy Improvement ở thuật toán Policy Iteration.
Xây dựng Value Iteration
Phần này tương đối đơn giản vì một phần là ta đã đi qua Policy Iteration, một phần là thuật toán này được xây dựng dựa trên đó.
Ở phần trước, chúng ta đã biết được 3 công thức quan trọng của Policy Iteration:
Công thức tính V:
V(s0)=EP[t∑γtR(st)]=∑P(s)γtR(s)
Công thức quan hệ giữa Value của State hiện tại và State kế tiếp:
Ở công thức (2), ta đã tính Value dựa trên Policy hiện tại là π, do đó sau mỗi lần cập nhật, ta phải lặp qua các State một lần nữa để sửa lại Policy cho lần tính Value tiếp theo.
Thay vì tính Value dựa trên một Action duy nhất theo Policy, chúng ta có thể tính Value trên toàn bộ Action, sau đó chọn ra Action cho ra Value cao nhất. Bằng cách triển khai này, ta sẽ có thể bỏ qua Policy.
Ý tưởng là vậy, hãy bắt đầu bằng việc triển khai công thức tính Value theo một Action ai cụ thể:
V(s0∣ai)=R(s0)+γ∑T(s1∣s0,ai)V(s1)
Khá đơn giản vì ta chỉ cần thay Action theo Policy là π(s0) bằng Action tuỳ ý là ai.
Phương trình trên còn được gọi là Bellman Equation (Phương trình Bellman), là tiền đề của rất nhiều lĩnh vực và thuật toán phức tạp sau này.
Từ đây, việc giải bài toán MDP chính là giải phương trình Bellman.
Value Evaluation
Khác với Policy Evaluation khi chúng ta có thể Giải hệ phương trình tuyến tính một cách dễ dàng, phương trình Bellman không cho phép làm vậy vì toán tử max.
Do đó, chúng ta sẽ phải sử dụng phương pháp Xấp xỉ Value để giải quyết bài toán này, đó cũng là lí do tại sao phương pháp phức tạp này lại được đề cập trong bài viết trước.
Trước hết, ta sẽ mượn lại bản đồ từ ví dụ trước (không cần quan tâm đến Policy nữa):
Ví dụ Policy trong game Pac-Man 2
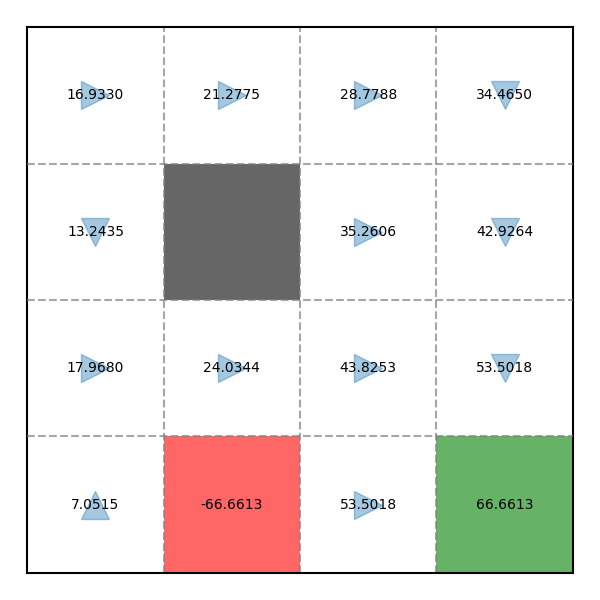
Ta sẽ chỉ liệt kê một State làm ví dụ, ở phần trước, V(11) được biểu diễn như sau:
Như vậy, sau mỗi lần quét, các Value sẽ hội tụ đến một "điểm tới hạn". Chúng ta có thể đặt một giá trị delta theo dõi sự thay đổi lớn nhất của các Value trong mỗi lần quét. Khi delta≤ϵ (trong đó ϵ là một giá trị rất nhỏ, có thể đặt là 10−3), ta có thể cho dừng thuật toán.
Kết luận
Kết quả của thuật toán Value Iteration sẽ hơi khác so với Policy Iteration một chút (có thể kiểm tra lại kết quả ở phần trước).
Policy Improvement
Value Iteration cũng sẽ có Policy Improvement với thuật toán hoàn toàn tương tự như Policy Iteration. Tuy nhiên thay vì chạy sau mỗi lần quét, ta sẽ chỉ chạy một lần duy nhất sau Value Evaluation khi các Value đã hội tụ.
Đây là kết quả cuối cùng, sau khi chạy Policy Improvement: